Introducing Mu language model and how it enabled the agent in Windows Settings
We are excited to introduce our newest on-device small language model, Mu. This model addresses scenarios that require inferring complex input-output relationships and has been designed to operate efficiently, delivering high performance while runnin The post Introducing Mu language model and how it enabled the agent in Windows Settings appeared first on Windows Blog.

We are excited to introduce our newest on-device small language model, Mu. This model addresses scenarios that require inferring complex input-output relationships and has been designed to operate efficiently, delivering high performance while running locally. Specifically, this is the language model that powers the agent in Settings, available to Windows Insiders in the Dev Channel with Copilot+ PCs, by mapping natural language input queries to Settings function calls.
Mu is fully offloaded onto the Neural Processing Unit (NPU) and responds at over 100 tokens per second, meeting the demanding UX requirements of the agent in Settings scenario. This blog will provide further details on Mu’s design and training and how it was fine-tuned to build the agent in Settings.
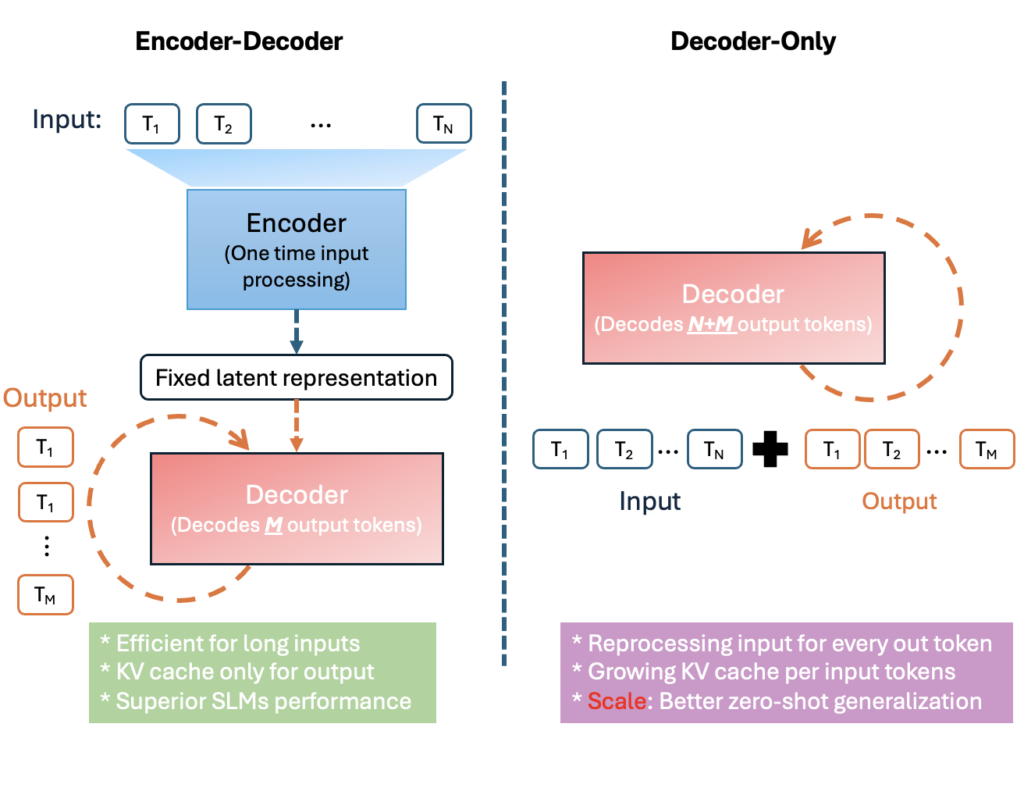 Encoder-Decoder Architecture compared to Decoder-only Architecture[/caption]
Mu is an efficient 330M encoder–decoder language model optimized for small-scale deployment, particularly on the NPUs on Copilot+ PCs. It follows a transformer encoder–decoder architecture, meaning an encoder first converts the input into a fixed-length latent representation, and a decoder then generates output tokens based on that representation.
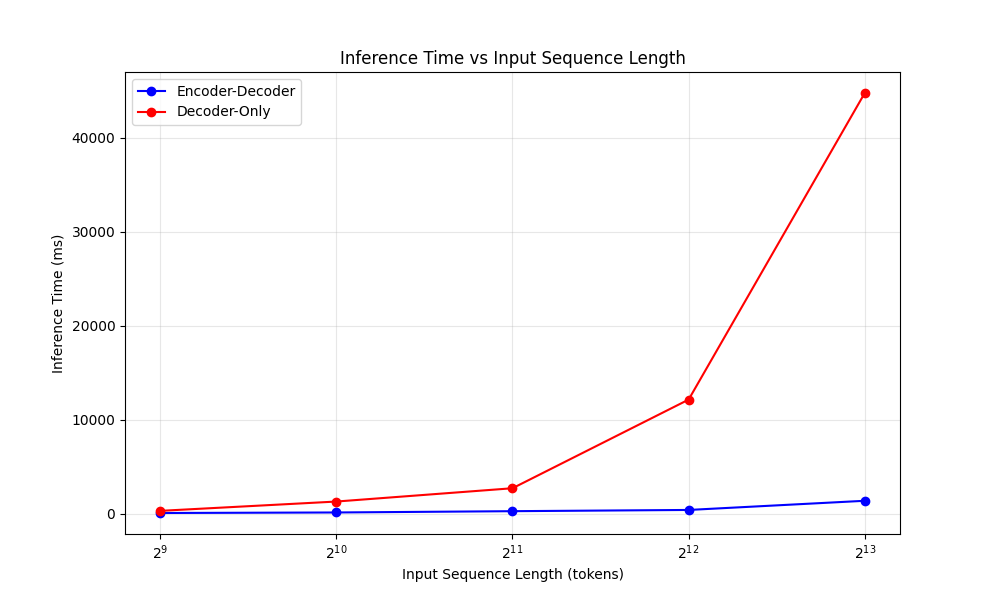
This design yields significant efficiency benefits. The figure above illustrates how an encoder-decoder reuses the input's latent representation whereas a decoder-only must consider the full input + output sequence. By separating the input tokens from output tokens, Mu’s one-time encoding greatly reduces computation and memory overhead. In practice, this translates to lower latency and higher throughput on specialized hardware. For example, on a Qualcomm Hexagon NPU (a mobile AI accelerator), Mu’s encoder–decoder approach achieved about 47% lower first-token latency and 4.7× higher decoding speed compared to a decoder-only model of similar size. These gains are crucial for on-device and real-time applications.
Mu’s design was carefully tuned for the constraints and capabilities of NPUs. This involved adjusting model architecture and parameter shapes to better fit the hardware’s parallelism and memory limits. We chose layer dimensions (such as hidden sizes and feed-forward network widths) that align with the NPU’s preferred tensor sizes and vectorization units, ensuring that matrix multiplications and other operations run at peak efficiency. We also optimized the parameter distribution between the encoder and decoder – empirically favoring a 2/3–1/3 split (e.g. 32 encoder layers vs 12 decoder layers in one configuration) to maximize performance per parameter.
Additionally, Mu employs weight sharing in certain components to reduce the total parameter count. For instance, it ties the input token embeddings and output embeddings, so that one set of weights is used for both representing input tokens and generating output logits. This not only saves memory (important on memory-constrained NPUs) but can also improve consistency between encoding and decoding vocabularies.
Finally, Mu restricts its operations to those NPU-optimized operators supported by the deployment runtime. By avoiding any unsupported or inefficient ops, Mu fully utilizes the NPU’s acceleration capabilities. These hardware-aware optimizations collectively make Mu highly suited for fast, on-device inference.
Encoder-Decoder Architecture compared to Decoder-only Architecture[/caption]
Mu is an efficient 330M encoder–decoder language model optimized for small-scale deployment, particularly on the NPUs on Copilot+ PCs. It follows a transformer encoder–decoder architecture, meaning an encoder first converts the input into a fixed-length latent representation, and a decoder then generates output tokens based on that representation.
This design yields significant efficiency benefits. The figure above illustrates how an encoder-decoder reuses the input's latent representation whereas a decoder-only must consider the full input + output sequence. By separating the input tokens from output tokens, Mu’s one-time encoding greatly reduces computation and memory overhead. In practice, this translates to lower latency and higher throughput on specialized hardware. For example, on a Qualcomm Hexagon NPU (a mobile AI accelerator), Mu’s encoder–decoder approach achieved about 47% lower first-token latency and 4.7× higher decoding speed compared to a decoder-only model of similar size. These gains are crucial for on-device and real-time applications.
Mu’s design was carefully tuned for the constraints and capabilities of NPUs. This involved adjusting model architecture and parameter shapes to better fit the hardware’s parallelism and memory limits. We chose layer dimensions (such as hidden sizes and feed-forward network widths) that align with the NPU’s preferred tensor sizes and vectorization units, ensuring that matrix multiplications and other operations run at peak efficiency. We also optimized the parameter distribution between the encoder and decoder – empirically favoring a 2/3–1/3 split (e.g. 32 encoder layers vs 12 decoder layers in one configuration) to maximize performance per parameter.
Additionally, Mu employs weight sharing in certain components to reduce the total parameter count. For instance, it ties the input token embeddings and output embeddings, so that one set of weights is used for both representing input tokens and generating output logits. This not only saves memory (important on memory-constrained NPUs) but can also improve consistency between encoding and decoding vocabularies.
Finally, Mu restricts its operations to those NPU-optimized operators supported by the deployment runtime. By avoiding any unsupported or inefficient ops, Mu fully utilizes the NPU’s acceleration capabilities. These hardware-aware optimizations collectively make Mu highly suited for fast, on-device inference.
 Mu adds three key transformer upgrades that squeeze more performance from a smaller model:
Mu adds three key transformer upgrades that squeeze more performance from a smaller model:
 Screenshot demonstrating the agent in Settings[/caption]
To further address the challenge of short and ambiguous user queries, we curated a diverse evaluation set combining real user inputs, synthetic queries and common settings, ensuring the model could handle a wide range of scenarios effectively. We observed that the model performed best on multi-word queries that conveyed clear intent, as opposed to short or partial-word inputs, which often lack sufficient context for accurate interpretation. To address this gap, the agent in Settings is integrated into the Settings search box, enabling short queries that don’t meet the multi-word threshold to continue to surface lexical and semantic search results in the search box, while allowing multi-word queries to surface the agent to return high precision actionable responses.
Managing the extensive array of Windows settings posed its own challenges, particularly with overlapping functionalities. For instance, even a simple query like "Increase brightness" could refer to multiple settings changes – if a user has dual monitors, does that mean increasing brightness to the primary monitor or a secondary monitor?
To address this, we refined our training data to prioritize the most used settings as we continue to refine the experience for more complex tasks.
Screenshot demonstrating the agent in Settings[/caption]
To further address the challenge of short and ambiguous user queries, we curated a diverse evaluation set combining real user inputs, synthetic queries and common settings, ensuring the model could handle a wide range of scenarios effectively. We observed that the model performed best on multi-word queries that conveyed clear intent, as opposed to short or partial-word inputs, which often lack sufficient context for accurate interpretation. To address this gap, the agent in Settings is integrated into the Settings search box, enabling short queries that don’t meet the multi-word threshold to continue to surface lexical and semantic search results in the search box, while allowing multi-word queries to surface the agent to return high precision actionable responses.
Managing the extensive array of Windows settings posed its own challenges, particularly with overlapping functionalities. For instance, even a simple query like "Increase brightness" could refer to multiple settings changes – if a user has dual monitors, does that mean increasing brightness to the primary monitor or a secondary monitor?
To address this, we refined our training data to prioritize the most used settings as we continue to refine the experience for more complex tasks.
Model training Mu
Enabling Phi Silica to run on NPUs provided us with valuable insights about tuning models for optimal performance and efficiency. These informed the development of Mu, a micro-sized, task-specific language model designed from the ground up to run efficiently on NPUs and edge devices. [caption id="attachment_179775" align="alignnone" width="1024"] Encoder-Decoder Architecture compared to Decoder-only Architecture[/caption]
Mu is an efficient 330M encoder–decoder language model optimized for small-scale deployment, particularly on the NPUs on Copilot+ PCs. It follows a transformer encoder–decoder architecture, meaning an encoder first converts the input into a fixed-length latent representation, and a decoder then generates output tokens based on that representation.
This design yields significant efficiency benefits. The figure above illustrates how an encoder-decoder reuses the input's latent representation whereas a decoder-only must consider the full input + output sequence. By separating the input tokens from output tokens, Mu’s one-time encoding greatly reduces computation and memory overhead. In practice, this translates to lower latency and higher throughput on specialized hardware. For example, on a Qualcomm Hexagon NPU (a mobile AI accelerator), Mu’s encoder–decoder approach achieved about 47% lower first-token latency and 4.7× higher decoding speed compared to a decoder-only model of similar size. These gains are crucial for on-device and real-time applications.
Mu’s design was carefully tuned for the constraints and capabilities of NPUs. This involved adjusting model architecture and parameter shapes to better fit the hardware’s parallelism and memory limits. We chose layer dimensions (such as hidden sizes and feed-forward network widths) that align with the NPU’s preferred tensor sizes and vectorization units, ensuring that matrix multiplications and other operations run at peak efficiency. We also optimized the parameter distribution between the encoder and decoder – empirically favoring a 2/3–1/3 split (e.g. 32 encoder layers vs 12 decoder layers in one configuration) to maximize performance per parameter.
Additionally, Mu employs weight sharing in certain components to reduce the total parameter count. For instance, it ties the input token embeddings and output embeddings, so that one set of weights is used for both representing input tokens and generating output logits. This not only saves memory (important on memory-constrained NPUs) but can also improve consistency between encoding and decoding vocabularies.
Finally, Mu restricts its operations to those NPU-optimized operators supported by the deployment runtime. By avoiding any unsupported or inefficient ops, Mu fully utilizes the NPU’s acceleration capabilities. These hardware-aware optimizations collectively make Mu highly suited for fast, on-device inference.
Packing performance in a tenth the size
Mu adds three key transformer upgrades that squeeze more performance from a smaller model:
- Dual LayerNorm (pre- and post-LN) – normalizing both before and after each sub-layer keeps activations well-scaled, stabilizing training with minimal overhead.
- Rotary Positional Embeddings (RoPE) – complex-valued rotations embed relative positions directly in attention, improving long-context reasoning and allowing seamless extrapolation to sequences longer than those seen in training.
- Grouped-Query Attention (GQA) – sharing keys / values across head groups slashes attention parameters and memory while preserving head diversity, cutting latency and power on NPUs.
| Task \ Model | Fine-tuned Mu | Fine-tuned Phi |
| SQUAD | 0.692 | 0.846 |
| CodeXGlue | 0.934 | 0.930 |
| Settings Agent | 0.738 | 0.815 |
Model quantization and model optimization
To enable the Mu model to run efficiently on-device, we applied advanced model quantization techniques tailored to NPUs on Copilot+ PCs. We used Post-Training Quantization (PTQ) to convert the model weights and activations from floating point to integer representations – primarily 8-bit and 16-bit. PTQ allowed us to take a fully trained model and quantize it without requiring retraining, significantly accelerating our deployment timeline and optimizing for efficiently running on Copilot+ devices. Ultimately, this approach preserved model accuracy while drastically reducing memory footprint and compute requirements without impacting the user experience. Quantization was just one part of the optimization pipeline. We also collaborated closely with our silicon partners at AMD, Intel and Qualcomm to ensure that the quantized operations when running Mu were fully optimized for the target NPUs. This included tuning mathematical operators, aligning with hardware-specific execution patterns and validating performance across different silicon. The optimization steps result in highly efficient inferences on edge devices, producing outputs at more than 200 tokens/second on a Surface Laptop 7. https://www.youtube.com/watch?si=P1nIObhNUVckI7yl&v=A2geTQes0Pw&feature=youtu.beMu running a question-answering task on an edge device, using context sourced from Wikipedia: (https://en.wikipedia.org/wiki/Microsoft) Notice the fast token throughputs and ultra-fast time to first token responses despite the large amount of input context provided to the model. By pairing state-of-the-art quantization techniques with hardware-specific optimizations, we ensured that Mu is highly effective for real-world deployments on resource-constrained applications. In the next section, we go into detail on how Mu was fine-tuned and applied to build the new Windows agent in Settings on Copilot+ PCs.
Model tuning the agent in Settings
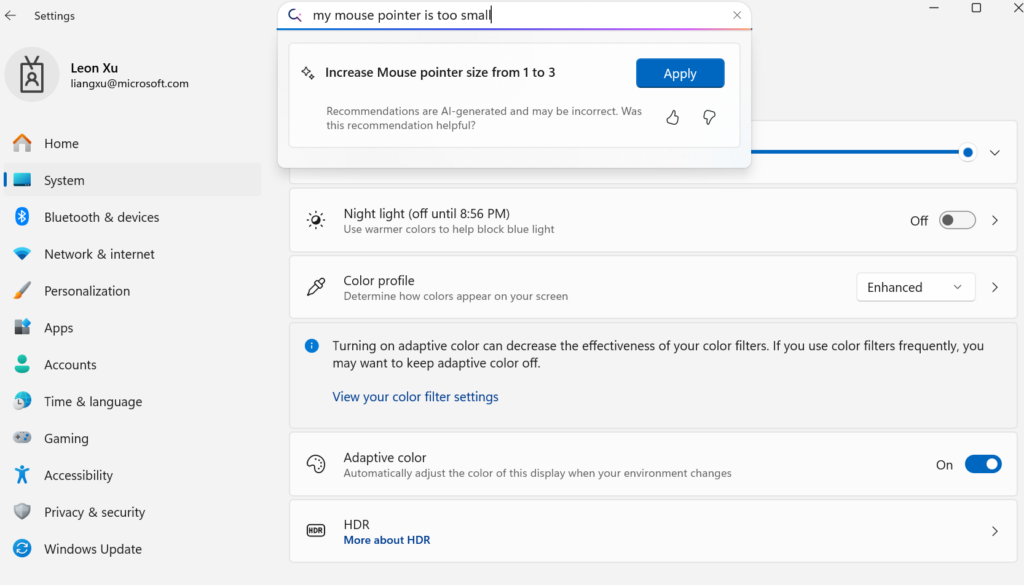
To improve Windows' ease of use, we focused on addressing the challenge of changing hundreds of system settings. Our goal was to create an AI-powered agent within Settings that understands natural language and changes relevant undoable settings seamlessly. We aimed to integrate this agent into the existing search box for a smooth user experience, requiring ultra-low latency for numerous possible settings. After testing various models, Phi LoRA initially met precision goals but was too large to meet latency targets. Mu, with the right characteristics, required task-specific tuning for optimal performance in Windows Settings. While baseline Mu in this scenario excelled in terms of performance and power footprint, it incurred a 2x precision drop using the same data without any fine-tuning. To close the gap, we scaled training to 3.6M samples (1300x) and expanded from roughly 50 settings to hundreds of settings. By employing synthetic approaches for automated labelling, prompt tuning with metadata, diverse phrasing, noise injection and smart sampling, the Mu fine-tune used for Settings Agent successfully met our quality objectives. The Mu model fine-tune achieved response times of under 500 milliseconds, aligning with our goals for a responsive and reliable agent in Settings that scaled to hundreds of settings. The below image shows how the experience is integrated with an example showing the mapping from a natural use language query to a Settings action being surfaced by the UI. [caption id="attachment_179778" align="alignnone" width="1024"] Screenshot demonstrating the agent in Settings[/caption]
To further address the challenge of short and ambiguous user queries, we curated a diverse evaluation set combining real user inputs, synthetic queries and common settings, ensuring the model could handle a wide range of scenarios effectively. We observed that the model performed best on multi-word queries that conveyed clear intent, as opposed to short or partial-word inputs, which often lack sufficient context for accurate interpretation. To address this gap, the agent in Settings is integrated into the Settings search box, enabling short queries that don’t meet the multi-word threshold to continue to surface lexical and semantic search results in the search box, while allowing multi-word queries to surface the agent to return high precision actionable responses.
Managing the extensive array of Windows settings posed its own challenges, particularly with overlapping functionalities. For instance, even a simple query like "Increase brightness" could refer to multiple settings changes – if a user has dual monitors, does that mean increasing brightness to the primary monitor or a secondary monitor?
To address this, we refined our training data to prioritize the most used settings as we continue to refine the experience for more complex tasks.